Saving Datasets and DataArrays to NetCDF¶
Objectives¶
Introduce an easy method for saving Datasets and DataArrays objects to NetCDF
Introduction¶
Saving your Datasets and DataArrays objects to NetCDF files couldn’t be simpler. The xarray module that we’ve been using to load NetCDF files provides methods for saving your Datasets and DataArrays as NetCDF files.
Here is the manual page on the subjet: http://xarray.pydata.org/en/stable/generated/xarray.Dataset.to_netcdf.html
The method ._to_netcdf( ) is available to both Datasets and DataArrays objects. So useful!
To complete this tutorial, you will need the monthly mean SSH and temperature/salinity output for March 2010, as well as the model grid parameters file. The ShortNames of the required datasets are:
ECCO_L4_SSH_LLC0090GRID_MONTHLY_V4R4
ECCO_L4_TEMP_SALINITY_LLC0090GRID_MONTHLY_V4R4
ECCO_L4_GEOMETRY_LLC0090GRID_V4R4
The ecco_access Python package (install it if needed) will handle download or retrieval of the necessary data.
Syntax¶
your_dataset.to_netcdf('/your_filepath/your_netcdf_filename.nc')
Saving an existing Dataset to NetCDF¶
First, let’s set up the environment and load a Dataset
[1]:
import numpy as np
import xarray as xr
from os.path import join,expanduser
import sys
import matplotlib.pyplot as plt
import json
import glob
import ecco_v4_py as ecco
import ecco_access as ea
# are you working in the AWS Cloud?
incloud_access = False
# indicate mode of access from PO.DAAC
# options are:
# 'download': direct download from internet to your local machine
# 'download_ifspace': like download, but only proceeds
# if your machine have sufficient storage
# 's3_open': access datasets in-cloud from an AWS instance
# 's3_open_fsspec': use jsons generated with fsspec and
# kerchunk libraries to speed up in-cloud access
# 's3_get': direct download from S3 in-cloud to an AWS instance
# 's3_get_ifspace': like s3_get, but only proceeds if your instance
# has sufficient storage
user_home_dir = expanduser('~')
download_dir = join(user_home_dir,'Downloads','ECCO_V4r4_PODAAC')
if incloud_access:
access_mode = 's3_open_fsspec'
download_root_dir = None
jsons_root_dir = join(user_home_dir,'MZZ')
else:
access_mode = 'download_ifspace'
download_root_dir = download_dir
jsons_root_dir = None
Now load a single tile (model tile 2) of monthly averaged THETA for March 2010.
[4]:
## Access datasets needed for this tutorial
ShortNames_list = ["ECCO_L4_GEOMETRY_LLC0090GRID_V4R4",\
"ECCO_L4_SSH_LLC0090GRID_MONTHLY_V4R4",\
"ECCO_L4_TEMP_SALINITY_LLC0090GRID_MONTHLY_V4R4"]
ds_dict = ea.ecco_podaac_to_xrdataset(ShortNames_list,\
StartDate='2010-03',EndDate='2010-03',\
mode=access_mode,\
download_root_dir=download_root_dir,\
jsons_root_dir=jsons_root_dir,\
max_avail_frac=0.5)
[5]:
# load Mar 2010 temperature/salinity monthly mean
ds_temp_sal_201003 = ds_dict[ShortNames_list[2]]
# select only potential temperature on tile 2 and load it into memory
# Note: the extra set of brackets around THETA creates an xarray Dataset
# (with a single data variable) rather than a DataArray
theta_dataset = ds_temp_sal_201003[['THETA']].isel(tile=2).load()
[6]:
type(theta_dataset)
[6]:
xarray.core.dataset.Dataset
Now that we’ve loaded theta_dataset, let’s save it in the current file directory with a new name.
[7]:
new_filename_1 = './test_output.nc'
print ('saving to ', new_filename_1)
theta_dataset.to_netcdf(path=new_filename_1)
print ('finished saving')
saving to ./test_output.nc
finished saving
It’s really that simple!
Saving a new custom Dataset to NetCDF¶
Now let’s create a new custom Dataset that with THETA, SSH and model grid parameter variables for a few tiles.
[8]:
ds_SSH_201003 = ds_dict[ShortNames_list[1]]
# merge SSH and THETA data variables into a new dataset, and select several tiles to load into memory
tiles_to_load = [0,1,2]
ds_SSH_THETA_201003 = xr.merge([ds_SSH_201003['SSH'],ds_temp_sal_201003['THETA']]).isel(tile=tiles_to_load).load()
# load grid parameters (for tiles 0,1,2 only)
ds_grid = ds_dict[ShortNames_list[0]].compute()
custom_dataset = xr.merge([ds_SSH_THETA_201003, ds_grid])
and now we can easily save it:
[9]:
new_filename_2 = './test_output_2.nc'
print ('saving to ', new_filename_2)
custom_dataset.to_netcdf(path=new_filename_2)
custom_dataset.close()
print ('finished saving')
saving to ./test_output_2.nc
finished saving
[10]:
custom_dataset
[10]:
<xarray.Dataset> Size: 25MB
Dimensions: (i: 90, j: 90, tile: 3, time: 1, k: 50, i_g: 90, j_g: 90, k_u: 50,
k_l: 50, k_p1: 51, nb: 4, nv: 2)
Coordinates: (12/21)
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* tile (tile) int32 12B 0 1 2
* time (time) datetime64[ns] 8B 2010-03-16T12:00:00
XC (tile, j, i) float32 97kB -111.6 -111.3 -110.9 ... 51.44 51.84
YC (tile, j, i) float32 97kB -88.24 -88.38 -88.52 ... 67.53 67.47
... ...
Zp1 (k_p1) float32 204B 0.0 -10.0 -20.0 ... -5.678e+03 -6.134e+03
Zu (k_u) float32 200B -10.0 -20.0 -30.0 ... -5.678e+03 -6.134e+03
Zl (k_l) float32 200B 0.0 -10.0 -20.0 ... -5.244e+03 -5.678e+03
XC_bnds (tile, j, i, nb) float32 389kB -115.0 -115.0 -107.9 ... 52.0 51.73
YC_bnds (tile, j, i, nb) float32 389kB -88.18 -88.32 -88.3 ... 67.5 67.56
Z_bnds (k, nv) float32 400B 0.0 -10.0 -10.0 ... -5.678e+03 -6.134e+03
Dimensions without coordinates: nb, nv
Data variables: (12/23)
SSH (time, tile, j, i) float32 97kB nan nan nan nan ... nan nan nan nan
THETA (time, k, tile, j, i) float32 5MB nan nan nan nan ... nan nan nan
CS (tile, j, i) float32 97kB 0.06158 0.06675 0.07293 ... 0.9052 0.9424
SN (tile, j, i) float32 97kB -0.9981 -0.9978 ... -0.4251 -0.3344
rA (tile, j, i) float32 97kB 3.623e+08 3.633e+08 ... 2.126e+08
dxG (tile, j_g, i) float32 97kB 1.558e+04 1.559e+04 ... 1.787e+04
... ...
hFacC (k, tile, j, i) float32 5MB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
hFacW (k, tile, j, i_g) float32 5MB 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
hFacS (k, tile, j_g, i) float32 5MB 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
maskC (k, tile, j, i) bool 1MB False False False ... False False False
maskW (k, tile, j, i_g) bool 1MB False False False ... False False False
maskS (k, tile, j_g, i) bool 1MB False False False ... False False False
Attributes:
long_name: Dynamic sea surface height anomaly
units: m
coverage_content_type: modelResult
standard_name: sea_surface_height_above_geoid
comment: Dynamic sea surface height anomaly above the geoi...
valid_min: -1.8805772066116333
valid_max: 1.4207719564437866Verifying our new NetCDF files¶
To verify that to_netcdf() worked, load them and compare with the originals.
Compare theta_dataset with dataset_1¶
[11]:
# the first test dataset
dataset_1 = xr.open_dataset(new_filename_1)
# release the file handle (not necessary but generally a good idea)
dataset_1.close()
The np.allclose method does element-by-element comparison of variables
[12]:
# loop through the data variables in dataset_1
for key in dataset_1.keys():
print ('checking %s ' % key)
print ('-- identical in dataset_1 and theta_dataset : %s' % \
np.allclose(dataset_1[key], theta_dataset[key], equal_nan=True))
# note: ``equal_nan`` means nan==nan (default nan != nan)
checking THETA
-- identical in dataset_1 and theta_dataset : True
THETA is the same in both datasets.
Compare custom_dataset with dataset_2¶
[13]:
# our custom dataset
dataset_2 = xr.open_dataset(new_filename_2)
dataset_2.close()
print ('finished loading')
finished loading
[14]:
for key in dataset_2.keys():
print ('checking %s ' % key)
print ('-- identical in dataset_2 and custom_dataset : %s'\
% np.allclose(dataset_2[key], custom_dataset[key], equal_nan=True))
checking SSH
-- identical in dataset_2 and custom_dataset : True
checking THETA
-- identical in dataset_2 and custom_dataset : True
checking CS
-- identical in dataset_2 and custom_dataset : True
checking SN
-- identical in dataset_2 and custom_dataset : True
checking rA
-- identical in dataset_2 and custom_dataset : True
checking dxG
-- identical in dataset_2 and custom_dataset : True
checking dyG
-- identical in dataset_2 and custom_dataset : True
checking Depth
-- identical in dataset_2 and custom_dataset : True
checking rAz
-- identical in dataset_2 and custom_dataset : True
checking dxC
-- identical in dataset_2 and custom_dataset : True
checking dyC
-- identical in dataset_2 and custom_dataset : True
checking rAw
-- identical in dataset_2 and custom_dataset : True
checking rAs
-- identical in dataset_2 and custom_dataset : True
checking drC
-- identical in dataset_2 and custom_dataset : True
checking drF
-- identical in dataset_2 and custom_dataset : True
checking PHrefC
-- identical in dataset_2 and custom_dataset : True
checking PHrefF
-- identical in dataset_2 and custom_dataset : True
checking hFacC
-- identical in dataset_2 and custom_dataset : True
checking hFacW
-- identical in dataset_2 and custom_dataset : True
checking hFacS
-- identical in dataset_2 and custom_dataset : True
checking maskC
-- identical in dataset_2 and custom_dataset : True
checking maskW
-- identical in dataset_2 and custom_dataset : True
checking maskS
-- identical in dataset_2 and custom_dataset : True
SSH and THETA are the same in both datasets, as are most of the grid parameters. But what’s happening with the masks (maskC, maskW, maskS)? Let’s check their data type in each of the datasets:
[15]:
print('custom_dataset.maskC.dtype: ' + str(custom_dataset.maskC.dtype))
print('custom_dataset.maskW.dtype: ' + str(custom_dataset.maskW.dtype))
print('custom_dataset.maskS.dtype: ' + str(custom_dataset.maskS.dtype))
print('dataset_2.maskC.dtype: ' + str(dataset_2.maskC.dtype))
print('dataset_2.maskW.dtype: ' + str(dataset_2.maskW.dtype))
print('dataset_2.maskS.dtype: ' + str(dataset_2.maskS.dtype))
custom_dataset.maskC.dtype: bool
custom_dataset.maskW.dtype: bool
custom_dataset.maskS.dtype: bool
dataset_2.maskC.dtype: bool
dataset_2.maskW.dtype: bool
dataset_2.maskS.dtype: bool
So for some reason after these boolean (bool) fields were saved in the file, they were re-opened as float32 floating-point numbers. Let’s fix this and then compare the masks again.
[16]:
dataset_2.maskC.data = dataset_2.maskC.data.astype('bool')
dataset_2.maskW.data = dataset_2.maskW.data.astype('bool')
dataset_2.maskS.data = dataset_2.maskS.data.astype('bool')
for key in dataset_2.keys():
print ('checking %s ' % key)
print ('-- identical in dataset_2 and custom_dataset : %s'\
% np.allclose(dataset_2[key], custom_dataset[key], equal_nan=True))
checking SSH
-- identical in dataset_2 and custom_dataset : True
checking THETA
-- identical in dataset_2 and custom_dataset : True
checking CS
-- identical in dataset_2 and custom_dataset : True
checking SN
-- identical in dataset_2 and custom_dataset : True
checking rA
-- identical in dataset_2 and custom_dataset : True
checking dxG
-- identical in dataset_2 and custom_dataset : True
checking dyG
-- identical in dataset_2 and custom_dataset : True
checking Depth
-- identical in dataset_2 and custom_dataset : True
checking rAz
-- identical in dataset_2 and custom_dataset : True
checking dxC
-- identical in dataset_2 and custom_dataset : True
checking dyC
-- identical in dataset_2 and custom_dataset : True
checking rAw
-- identical in dataset_2 and custom_dataset : True
checking rAs
-- identical in dataset_2 and custom_dataset : True
checking drC
-- identical in dataset_2 and custom_dataset : True
checking drF
-- identical in dataset_2 and custom_dataset : True
checking PHrefC
-- identical in dataset_2 and custom_dataset : True
checking PHrefF
-- identical in dataset_2 and custom_dataset : True
checking hFacC
-- identical in dataset_2 and custom_dataset : True
checking hFacW
-- identical in dataset_2 and custom_dataset : True
checking hFacS
-- identical in dataset_2 and custom_dataset : True
checking maskC
-- identical in dataset_2 and custom_dataset : True
checking maskW
-- identical in dataset_2 and custom_dataset : True
checking maskS
-- identical in dataset_2 and custom_dataset : True
Now we can confirm that all the variables in the datasets match!
Saving the results of calculations¶
Calculations in the form of DataArrays¶
Often we would like to store the results of our calculations to disk. If your operations are made at the level of DataArray objects (and not the lower ndarray level) then you can use these same methods to save your results. All of the coordinates will be preserved (although attributes be lost). Let’s demonstrate by making a dummy calculation on SSH
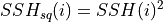
[17]:
SSH_sq = custom_dataset.SSH * custom_dataset.SSH
SSH_sq
[17]:
<xarray.DataArray 'SSH' (time: 1, tile: 3, j: 90, i: 90)> Size: 97kB
array([[[[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
...,
[2.0671911 , 2.0848224 , 2.0841086 , ..., 1.7935177 ,
1.7659562 , 1.739012 ],
[1.9880351 , 2.0051208 , 2.002616 , ..., 1.7589175 ,
1.7311752 , 1.7012385 ],
[1.8994561 , 1.9122815 , 1.9098864 , ..., 1.7312655 ,
1.7034038 , 1.6693714 ]],
[[1.8020678 , 1.810736 , 1.8133253 , ..., 1.7026882 ,
1.6756296 , 1.6379843 ],
[1.7121627 , 1.719325 , 1.7317982 , ..., 1.6670871 ,
1.6423833 , 1.6031213 ],
[1.6535913 , 1.6606174 , 1.6836028 , ..., 1.6204541 ,
1.5996994 , 1.5617636 ],
...
[0.0358197 , 0.03125747, 0.02652959, ..., nan,
0.28220004, 0.31124577],
[0.02917161, 0.02486313, 0.02061234, ..., nan,
0.2443076 , 0.2719567 ],
[0.02321114, 0.01939201, 0.01575851, ..., nan,
nan, 0.23898326]],
[[0.01884312, 0.01536459, 0.01223672, ..., nan,
nan, 0.2193556 ],
[0.01608207, 0.01280527, 0.0099735 , ..., 0.151336 ,
nan, 0.20633157],
[0.01495756, 0.01177618, 0.00917115, ..., 0.16071834,
0.1699125 , 0.20213497],
...,
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan]]]], dtype=float32)
Coordinates:
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* tile (tile) int32 12B 0 1 2
* time (time) datetime64[ns] 8B 2010-03-16T12:00:00
XC (tile, j, i) float32 97kB -111.6 -111.3 -110.9 ... 51.44 51.84
YC (tile, j, i) float32 97kB -88.24 -88.38 -88.52 ... 67.53 67.47SSH_sq is itself a DataArray.
Before saving, let’s give our new SSH_sq variable a better name and descriptive attributes.
[18]:
SSH_sq.name = 'SSH^2'
SSH_sq.attrs['long_name'] = 'Square of Surface Height Anomaly'
SSH_sq.attrs['units'] = 'm^2'
# Let's see the result
SSH_sq
[18]:
<xarray.DataArray 'SSH^2' (time: 1, tile: 3, j: 90, i: 90)> Size: 97kB
array([[[[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
...,
[2.0671911 , 2.0848224 , 2.0841086 , ..., 1.7935177 ,
1.7659562 , 1.739012 ],
[1.9880351 , 2.0051208 , 2.002616 , ..., 1.7589175 ,
1.7311752 , 1.7012385 ],
[1.8994561 , 1.9122815 , 1.9098864 , ..., 1.7312655 ,
1.7034038 , 1.6693714 ]],
[[1.8020678 , 1.810736 , 1.8133253 , ..., 1.7026882 ,
1.6756296 , 1.6379843 ],
[1.7121627 , 1.719325 , 1.7317982 , ..., 1.6670871 ,
1.6423833 , 1.6031213 ],
[1.6535913 , 1.6606174 , 1.6836028 , ..., 1.6204541 ,
1.5996994 , 1.5617636 ],
...
[0.0358197 , 0.03125747, 0.02652959, ..., nan,
0.28220004, 0.31124577],
[0.02917161, 0.02486313, 0.02061234, ..., nan,
0.2443076 , 0.2719567 ],
[0.02321114, 0.01939201, 0.01575851, ..., nan,
nan, 0.23898326]],
[[0.01884312, 0.01536459, 0.01223672, ..., nan,
nan, 0.2193556 ],
[0.01608207, 0.01280527, 0.0099735 , ..., 0.151336 ,
nan, 0.20633157],
[0.01495756, 0.01177618, 0.00917115, ..., 0.16071834,
0.1699125 , 0.20213497],
...,
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan]]]], dtype=float32)
Coordinates:
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* tile (tile) int32 12B 0 1 2
* time (time) datetime64[ns] 8B 2010-03-16T12:00:00
XC (tile, j, i) float32 97kB -111.6 -111.3 -110.9 ... 51.44 51.84
YC (tile, j, i) float32 97kB -88.24 -88.38 -88.52 ... 67.53 67.47
Attributes:
long_name: Square of Surface Height Anomaly
units: m^2much better! Now we’ll save.
[19]:
new_filename_3 = './ssh_sq_DataArray.nc'
print ('saving to ', new_filename_3)
SSH_sq.to_netcdf(path=new_filename_3)
print ('finished saving')
saving to ./ssh_sq_DataArray.nc
finished saving
Calculations in the form of numpy ndarrays¶
If calculations are made at the ndarray level then the results will also be ndarrays.
[20]:
SSH_dummy_ndarray = custom_dataset.SSH.values * custom_dataset.SSH.values
type(SSH_dummy_ndarray)
[20]:
numpy.ndarray
You’ll need to use different methods to save these results to NetCDF files, one of which is described here: http://pyhogs.github.io/intro_netcdf4.html
Summary¶
Saving Datasets and DataArrays to disk as NetCDF files is fun and easy with xarray!