Combining multiple Datasets¶
Objectives:¶
Show how to combine multiple ECCO v4 state estimate Datasets after loading.
Opening multiple Datasets centered on different coordinates¶
In previous tutorials we’ve loaded single lat-lon-cap NetCDF tile files (granules) for ECCO state estimate variables and model grid parameters. Here we will demonstrate merging Datasets together. Some benefits of merging Datasets include having a tidier workspace and simplifying subsetting operations (e.g., using xarray.isel or xarray.sel as shown in the previous
tutorial).
First, we’ll load three ECCOv4 NetCDF state estimate variables (each centered on different coordinates) as well as the model grid file. For this, you will need 2 datasets of monthly mean fields for the year 2010, as well as the grid parameters file. The ShortNames for the datasets are:
ECCO_L4_GEOMETRY_LLC0090GRID_V4R4 (no time dimension)
ECCO_L4_SSH_LLC0090GRID_MONTHLY_V4R4 (Jan-Dec 2010)
ECCO_L4_OCEAN_3D_TEMPERATURE_FLUX_LLC0090GRID_MONTHLY_V4R4 (Jan-Dec 2010)
The ecco_access Python package will handle download or retrieval of the necessary data.
Let’s define our environment:
[1]:
import numpy as np
import xarray as xr
from os.path import join,expanduser
import sys
import matplotlib.pyplot as plt
import json
import ecco_v4_py as ecco
import ecco_access as ea
# are you working in the AWS Cloud?
incloud_access = False
# indicate mode of access from PO.DAAC
# options are:
# 'download': direct download from internet to your local machine
# 'download_ifspace': like download, but only proceeds
# if your machine have sufficient storage
# 's3_open': access datasets in-cloud from an AWS instance
# 's3_open_fsspec': use jsons generated with fsspec and
# kerchunk libraries to speed up in-cloud access
# 's3_get': direct download from S3 in-cloud to an AWS instance
# 's3_get_ifspace': like s3_get, but only proceeds if your instance
# has sufficient storage
user_home_dir = expanduser('~')
download_dir = join(user_home_dir,'Downloads','ECCO_V4r4_PODAAC')
if incloud_access:
access_mode = 's3_open_fsspec'
download_root_dir = None
jsons_root_dir = join(user_home_dir,'MZZ')
else:
access_mode = 'download_ifspace'
download_root_dir = download_dir
jsons_root_dir = None
[4]:
## Access datasets needed for this tutorial
ShortNames_list = ["ECCO_L4_GEOMETRY_LLC0090GRID_V4R4",\
"ECCO_L4_SSH_LLC0090GRID_MONTHLY_V4R4",\
"ECCO_L4_OCEAN_3D_TEMPERATURE_FLUX_LLC0090GRID_MONTHLY_V4R4"]
ds_dict = ea.ecco_podaac_to_xrdataset(ShortNames_list,\
StartDate='2010-01',EndDate='2010-12',\
mode=access_mode,\
download_root_dir=download_root_dir,\
jsons_root_dir=jsons_root_dir,\
max_avail_frac=0.5)
Open c point variable: SSH¶
[5]:
# load dataset containing monthly SSH in 2010
ecco_dataset_A = ds_dict[ShortNames_list[1]]
to see the data variables in a dataset, use .data_vars:
[6]:
ecco_dataset_A.data_vars
[6]:
Data variables:
SSH (time, tile, j, i) float32 5MB dask.array<chunksize=(1, 13, 90, 90), meta=np.ndarray>
SSHIBC (time, tile, j, i) float32 5MB dask.array<chunksize=(1, 13, 90, 90), meta=np.ndarray>
SSHNOIBC (time, tile, j, i) float32 5MB dask.array<chunksize=(1, 13, 90, 90), meta=np.ndarray>
ETAN (time, tile, j, i) float32 5MB dask.array<chunksize=(1, 13, 90, 90), meta=np.ndarray>
ecco_dataset_A has four data variables, all having dimensions i, j, tile, and time, which mean that they are centered with respect to the grid cells of the model. The coordinates associated with the SSH variable are:
[7]:
ecco_dataset_A.SSH.coords
[7]:
Coordinates:
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* tile (tile) int32 52B 0 1 2 3 4 5 6 7 8 9 10 11 12
* time (time) datetime64[ns] 96B 2010-01-16T12:00:00 ... 2010-12-16T12:...
XC (tile, j, i) float32 421kB dask.array<chunksize=(13, 90, 90), meta=np.ndarray>
YC (tile, j, i) float32 421kB dask.array<chunksize=(13, 90, 90), meta=np.ndarray>
You can see the coordinates that are also dimensions (dimensional coordinates) have an asterisk. The non-dimensional coordinates XC and YC are not used for indexing, but are very important as they indicate the longitude and latitude respectively associated with the dimensional coordinates.
Open u and v point variables: ADVx_TH and ADVy_TH¶
Now let’s open the ECCOv4 output files containing the horizontal advective fluxes of potential temperature, ADVx_TH and ADVy_TH.
[8]:
# open dataset containing monthly mean 3D temperature fluxes in 2010
ecco_dataset_B = ds_dict[ShortNames_list[2]]
ecco_dataset_B.data_vars
[8]:
Data variables:
ADVx_TH (time, k, tile, j, i_g) float32 253MB dask.array<chunksize=(1, 25, 7, 45, 45), meta=np.ndarray>
DFxE_TH (time, k, tile, j, i_g) float32 253MB dask.array<chunksize=(1, 25, 7, 45, 45), meta=np.ndarray>
ADVy_TH (time, k, tile, j_g, i) float32 253MB dask.array<chunksize=(1, 25, 7, 45, 45), meta=np.ndarray>
DFyE_TH (time, k, tile, j_g, i) float32 253MB dask.array<chunksize=(1, 25, 7, 45, 45), meta=np.ndarray>
ADVr_TH (time, k_l, tile, j, i) float32 253MB dask.array<chunksize=(1, 25, 7, 45, 45), meta=np.ndarray>
DFrE_TH (time, k_l, tile, j, i) float32 253MB dask.array<chunksize=(1, 25, 7, 45, 45), meta=np.ndarray>
DFrI_TH (time, k_l, tile, j, i) float32 253MB dask.array<chunksize=(1, 25, 7, 45, 45), meta=np.ndarray>
ecco_dataset_B has seven data variables! These include three variables (starting with AD) that quantify 3D advection fluxes, and four variables (starting with DF) that quantify 3D diffusive fluxes, including one DFrI_TH that is an implicit flux from the vertical mixing parameterization of the model. In this tutorial we will focus on the two variables that quantify horizontal advective fluxes.
Let’s look at one of these variables, ADVx_TH
[9]:
ecco_dataset_B.ADVx_TH
[9]:
<xarray.DataArray 'ADVx_TH' (time: 12, k: 50, tile: 13, j: 90, i_g: 90)> Size: 253MB
dask.array<concatenate, shape=(12, 50, 13, 90, 90), dtype=float32, chunksize=(1, 25, 7, 45, 45), chunktype=numpy.ndarray>
Coordinates:
* i_g (i_g) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* k (k) int32 200B 0 1 2 3 4 5 6 7 8 9 ... 41 42 43 44 45 46 47 48 49
* tile (tile) int32 52B 0 1 2 3 4 5 6 7 8 9 10 11 12
* time (time) datetime64[ns] 96B 2010-01-16T12:00:00 ... 2010-12-16T12:...
Z (k) float32 200B dask.array<chunksize=(50,), meta=np.ndarray>
Attributes:
long_name: Lateral advective flux of potential temperature i...
units: degree_C m3 s-1
mate: ADVy_TH
coverage_content_type: modelResult
direction: >0 increases potential temperature (THETA)
comment: Lateral advective flux of potential temperature (...
valid_min: -28231902.0
valid_max: 36523468.0The long_name and the comment tell us that this variable is the advective flux of potential temperature in the model +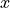 direction. It has dimensional coordinates i_g, j, k, tile, and time. The k dimension indexes depth (which was not a part of the
direction. It has dimensional coordinates i_g, j, k, tile, and time. The k dimension indexes depth (which was not a part of the SSH dataset), and the i_g dimension has replaced the i dimension that SSH had.
Since ADVx_TH has a i_g dimensional coordinate instead of i, we know that the flux is quantified not at the center of each cell, but is offset in the model direction. Specifically, the flux is quantified on the left or “west” face of each grid cell. In this context “west” may not actually refer to geographical west, but rather the left side of a grid cell on an axis where i and i_g increase to the right.
Now consider ADVy_TH:
[10]:
ecco_dataset_B.ADVy_TH
[10]:
<xarray.DataArray 'ADVy_TH' (time: 12, k: 50, tile: 13, j_g: 90, i: 90)> Size: 253MB
dask.array<concatenate, shape=(12, 50, 13, 90, 90), dtype=float32, chunksize=(1, 25, 7, 45, 45), chunktype=numpy.ndarray>
Coordinates:
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j_g (j_g) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* k (k) int32 200B 0 1 2 3 4 5 6 7 8 9 ... 41 42 43 44 45 46 47 48 49
* tile (tile) int32 52B 0 1 2 3 4 5 6 7 8 9 10 11 12
* time (time) datetime64[ns] 96B 2010-01-16T12:00:00 ... 2010-12-16T12:...
Z (k) float32 200B dask.array<chunksize=(50,), meta=np.ndarray>
Attributes:
long_name: Lateral advective flux of potential temperature i...
units: degree_C m3 s-1
mate: ADVx_TH
coverage_content_type: modelResult
direction: >0 increases potential temperature (THETA)
comment: Lateral advective flux of potential temperature (...
valid_min: -31236064.0
valid_max: 43466144.0ADVy_TH is the horizontal advective flux of potential temperature in each tile’s 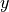 direction. The dimensional coordinates are i, j_g, k, tile, and time. In this case we have the centered coordinate i but the off-center (shifted) coordinate j_g, which indicates that these fluxes are located on the lower or “south” face of each grid cell—again with the caveat that this does not always correspond to geographical south.
direction. The dimensional coordinates are i, j_g, k, tile, and time. In this case we have the centered coordinate i but the off-center (shifted) coordinate j_g, which indicates that these fluxes are located on the lower or “south” face of each grid cell—again with the caveat that this does not always correspond to geographical south.
Examining the dimensions and coordinates of these Datasets¶
Each of the three variables we have discussed comprises an xarray DataArray, and each of these DataArray objects has different horizontal dimension labels.
i and j for SSH
i_g and j for ADVx_TH
i and j_g for ADVy_TH
[11]:
# print just the first line of each DataArray's information
print((str(ecco_dataset_A.SSH)).split('\n')[0])
print((str(ecco_dataset_B.ADVx_TH)).split('\n')[0])
print((str(ecco_dataset_B.ADVy_TH)).split('\n')[0])
<xarray.DataArray 'SSH' (time: 12, tile: 13, j: 90, i: 90)> Size: 5MB
<xarray.DataArray 'ADVx_TH' (time: 12, k: 50, tile: 13, j: 90, i_g: 90)> Size: 253MB
<xarray.DataArray 'ADVy_TH' (time: 12, k: 50, tile: 13, j_g: 90, i: 90)> Size: 253MB
Merging multiple Datasets from state estimate variables¶
Using the xarray method merge we can create a single Dataset with multiple DataArrays.
[12]:
# merge together and load into memory
ecco_dataset_AB = xr.merge([ecco_dataset_A['SSH'], ecco_dataset_B[['ADVx_TH','ADVy_TH']]]).compute()
Note: There are multiple syntaxes for selecting individual variables/DataArrays from an
xarraydataset. In the case of SSH above, see that we used bothecco_dataset_A.SSHandecco_dataset_A['SSH'], they indicate the same DataArray. The bracket syntax has the advantage of allowing you to create a subset dataset with multiple variables, by passing a list of the variable names, e.g.,ecco_dataset_B[['ADVx_TH','ADVy_TH']].
Examining the merged Dataset¶
As before, let’s look at the contents of the new merged Dataset
[13]:
ecco_dataset_AB
[13]:
<xarray.Dataset> Size: 512MB
Dimensions: (i: 90, j: 90, tile: 13, time: 12, k: 50, i_g: 90, j_g: 90)
Coordinates:
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* tile (tile) int32 52B 0 1 2 3 4 5 6 7 8 9 10 11 12
* time (time) datetime64[ns] 96B 2010-01-16T12:00:00 ... 2010-12-16T12:...
XC (tile, j, i) float32 421kB -111.6 -111.3 -110.9 ... -105.6 -111.9
YC (tile, j, i) float32 421kB -88.24 -88.38 -88.52 ... -88.08 -88.1
* i_g (i_g) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j_g (j_g) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* k (k) int32 200B 0 1 2 3 4 5 6 7 8 9 ... 41 42 43 44 45 46 47 48 49
XG (tile, j_g, i_g) float32 421kB -115.0 -115.0 ... -102.9 -109.0
YG (tile, j_g, i_g) float32 421kB -88.18 -88.32 ... -87.99 -88.02
Z (k) float32 200B -5.0 -15.0 -25.0 ... -5.461e+03 -5.906e+03
Data variables:
SSH (time, tile, j, i) float32 5MB nan nan nan nan ... nan nan nan nan
ADVx_TH (time, k, tile, j, i_g) float32 253MB nan nan nan ... nan nan nan
ADVy_TH (time, k, tile, j_g, i) float32 253MB nan nan nan ... nan nan nan
Attributes:
long_name: Dynamic sea surface height anomaly
units: m
coverage_content_type: modelResult
standard_name: sea_surface_height_above_geoid
comment: Dynamic sea surface height anomaly above the geoi...
valid_min: -1.8805772066116333
valid_max: 1.42077195644378661. Dimensions¶
Dimensions: (i: 90, j: 90, tile: 13, time: 12, i_g: 90, k: 50, j_g: 90)
ecco_dataset_merged is a container of DataArrays and as such it lists all of the unique dimensions its DataArrays. In other words, Dimensions shows all of the dimensions used by its variables.
2. Dimension Coordinates¶
Coordinates:
i (i) int32 0 1 2 3 4 5 6 7 8 9 … 80 81 82 83 84 85 86 87 88 89
j (j) int32 0 1 2 3 4 5 6 7 8 9 … 80 81 82 83 84 85 86 87 88 89
tile (tile) int32 0 1 2 3 4 5 6 7 8 9 10 11 12
time (time) datetime64[ns] 2010-01-16T12:00:00 … 2010-12-16T12:00:00
i_g (i_g) int32 0 1 2 3 4 5 6 7 8 9 … 80 81 82 83 84 85 86 87 88 89
k (k) int32 0 1 2 3 4 5 6 7 8 9 … 40 41 42 43 44 45 46 47 48 49
j_g (j_g) int32 0 1 2 3 4 5 6 7 8 9 … 80 81 82 83 84 85 86 87 88 89
Notice that the tile and time coordinates are unchanged. merge recognizes identical coordiantes and keeps them.
3. Non-Dimension Coordinates¶
XC (tile, j, i) float32 -111.60647 -111.303 -110.94285 … nan nan
YC (tile, j, i) float32 -88.24259 -88.382515 -88.52242 … nan nan
Z (k) float32 -5.0 -15.0 -25.0 -35.0 … -5039.25 -5461.25 -5906.25
The list of non-dimension coordinates includes the horizontal and vertical coordinates needed to locate each grid cell in geographical space. Like Dimensions, the non-dimension coordinates of the merged Dataset contain all of the non-dimension coordinates of the DataArrays. Notice that the horizontal coordinates of the grid corners (XG,YG) are not included, since they weren’t in any of the source DataArrays.
4. Attributes¶
Note that the high-level attributes of the new Dataset are just the attributes of the first DataArray in the merge, the SSH DataArray. The attributes of the Data variables remain intact:
[14]:
# (this json command makes Python dictionaries easier to read)
print(json.dumps(ecco_dataset_AB.ADVx_TH.attrs, indent=2,sort_keys=True))
{
"comment": "Lateral advective flux of potential temperature (THETA) in the +x direction through the 'u' face of the tracer cell on the native model grid. Note: in the Arakawa-C grid, horizontal flux quantities are staggered relative to the tracer cells with indexing such that +ADVx_TH(i_g,j,k) corresponds to +x fluxes through the 'u' face of the tracer cell at (i,j,k). Also, the model +x direction does not necessarily correspond to the geographical east-west direction because the x and y axes of the model's lat-lon-cap (llc) curvilinear lat-lon-cap (llc) grid have arbitrary orientations which vary within and across tiles.",
"coverage_content_type": "modelResult",
"direction": ">0 increases potential temperature (THETA)",
"long_name": "Lateral advective flux of potential temperature in the model +x direction",
"mate": "ADVy_TH",
"units": "degree_C m3 s-1",
"valid_max": 36523468.0,
"valid_min": -28231902.0
}
Adding the model grid Dataset¶
Let’s use the merge routine to combine a Dataset of the model grid parameters with output_merged.
Load the model grid parameters¶
[15]:
# Load the llc90 grid parameters
grid_dataset = ds_dict[ShortNames_list[0]].compute()
grid_dataset.coords
[15]:
Coordinates:
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* i_g (i_g) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j_g (j_g) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* k (k) int32 200B 0 1 2 3 4 5 6 7 8 9 ... 41 42 43 44 45 46 47 48 49
* k_u (k_u) int32 200B 0 1 2 3 4 5 6 7 8 9 ... 41 42 43 44 45 46 47 48 49
* k_l (k_l) int32 200B 0 1 2 3 4 5 6 7 8 9 ... 41 42 43 44 45 46 47 48 49
* k_p1 (k_p1) int32 204B 0 1 2 3 4 5 6 7 8 ... 42 43 44 45 46 47 48 49 50
* tile (tile) int32 52B 0 1 2 3 4 5 6 7 8 9 10 11 12
XC (tile, j, i) float32 421kB ...
YC (tile, j, i) float32 421kB ...
XG (tile, j_g, i_g) float32 421kB ...
YG (tile, j_g, i_g) float32 421kB ...
Z (k) float32 200B ...
Zp1 (k_p1) float32 204B ...
Zu (k_u) float32 200B ...
Zl (k_l) float32 200B ...
XC_bnds (tile, j, i, nb) float32 2MB ...
YC_bnds (tile, j, i, nb) float32 2MB ...
Z_bnds (k, nv) float32 400B ...
Merge grid_all_tiles with output_merged¶
[16]:
ecco_dataset_ABG = xr.merge([ecco_dataset_AB, grid_dataset])
ecco_dataset_ABG
[16]:
<xarray.Dataset> Size: 599MB
Dimensions: (i: 90, j: 90, tile: 13, time: 12, k: 50, i_g: 90, j_g: 90,
k_u: 50, k_l: 50, k_p1: 51, nb: 4, nv: 2)
Coordinates: (12/21)
* i (i) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* j (j) int32 360B 0 1 2 3 4 5 6 7 8 9 ... 81 82 83 84 85 86 87 88 89
* tile (tile) int32 52B 0 1 2 3 4 5 6 7 8 9 10 11 12
* time (time) datetime64[ns] 96B 2010-01-16T12:00:00 ... 2010-12-16T12:...
XC (tile, j, i) float32 421kB -111.6 -111.3 -110.9 ... -105.6 -111.9
YC (tile, j, i) float32 421kB -88.24 -88.38 -88.52 ... -88.08 -88.1
... ...
Zp1 (k_p1) float32 204B ...
Zu (k_u) float32 200B ...
Zl (k_l) float32 200B ...
XC_bnds (tile, j, i, nb) float32 2MB ...
YC_bnds (tile, j, i, nb) float32 2MB ...
Z_bnds (k, nv) float32 400B ...
Dimensions without coordinates: nb, nv
Data variables: (12/24)
SSH (time, tile, j, i) float32 5MB nan nan nan nan ... nan nan nan nan
ADVx_TH (time, k, tile, j, i_g) float32 253MB nan nan nan ... nan nan nan
ADVy_TH (time, k, tile, j_g, i) float32 253MB nan nan nan ... nan nan nan
CS (tile, j, i) float32 421kB ...
SN (tile, j, i) float32 421kB ...
rA (tile, j, i) float32 421kB ...
... ...
hFacC (k, tile, j, i) float32 21MB ...
hFacW (k, tile, j, i_g) float32 21MB ...
hFacS (k, tile, j_g, i) float32 21MB ...
maskC (k, tile, j, i) bool 5MB ...
maskW (k, tile, j, i_g) bool 5MB ...
maskS (k, tile, j_g, i) bool 5MB ...
Attributes:
long_name: Dynamic sea surface height anomaly
units: m
coverage_content_type: modelResult
standard_name: sea_surface_height_above_geoid
comment: Dynamic sea surface height anomaly above the geoi...
valid_min: -1.8805772066116333
valid_max: 1.4207719564437866Examining the merged Dataset¶
The result of this last merge is a single Dataset with 3 Data variables, and a complete set of model grid parameters (geographical coordinates, distances, areas), including the coordinates of the grid cell corners XG,YG.
Merging and memory¶
Merging Datasets together does not make copies of the data in memory. Instead, merged Datasets are in fact just a reorganized collection of pointers. You may want to delete the original variables to clear your namespace, but it is not necessary.
Summary¶
Now you know how to merge multiple Datasets using the merge command. We demonstrated merging of Datasets constructed from three different variables types and the model grid parameters.